The day before my vacation me and my team had probably everything in place to let our cloud solution run for two weeks. The only missing peace was the “initial load”. As this is a cache based solution, data from a source system must be preloaded into the system as a whole.
You may think why not lazy load? There are advantages and disadvantages – for the time being a cache that consistently and reliably keeps all data seems to be the most obvious solution.
So we started it up. It was 12 o’clock in the middle of the night when I had everything ready. Started the load, the system raised messages onto the an azure cloud queue that we had chosen due to performance and scalability over the service bus. That looks good I was thinking at half past 12. Time for bed.
There are about 800.000 messages that will be added to the cloud queue when starting the initial load. These messages are processed by (currently) two “worker” instances. Summarized that meant that approximately 90-100 message per second are processed. So let’s assume it would be 100, it should be done in a little more than two hours.
Back at the desk next morning I was starring at the screen. The system was still alive and working but the maximum messages havn’t been 800.000 messages. The peak has been at 1.300.000 messages. The peak actually never should be reached as messages are already processed when the initial load starts to add messages to the queue. I really was scratching my head. What was going on?
I decided to wait another hour and watch what the system does. We use Stackify for monitoring log and errors in realtime. Additionally I kept an eye on the azure portal about the message count in the queue. I really couldn’t explain myself what I’ve seen there are after a while:
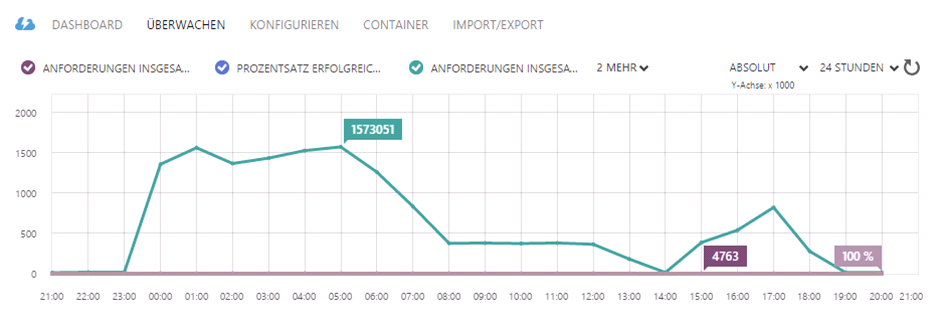
I expected the system to have reached the peak after some time. Filling up the cloud queue would not be done in a millisecond, it takes minutes – at the end ca. 45 minutes. After that time (at 1:00 am in the morning) there was another peak I couldn’t explain myself. And then another at 5:00 a.m, having 1.500.000 messages in the cloud queue. Who was adding messages? Did anybody accidentally started the initial load again?
After having waited another hour it was half past nine. I was starring at the graph telling me it now was moreless linear – the amount of messages being added to the queue must be the same than the processed ones – have a look between 8 and 12 o’clock.
I had a look onto my code. Everything fine. Still starring.
And then I had to smile, what a silly mistake.
The solution was pretty simple:
The initial load is being processed by a service bus message. To ensure the message is sent and processed the service bus implementation maintains a time out for each single message that is going to be processed. When the time has elapsed – in this case it is a minute – the service bus assumes that the worker processing that message is not responsive anymore, takes away that message and sends it again.
At the end the system processed about 15.000.000 messages. A small fix changed the behaviour and the initial load runs as expected in 2 1/2 hours.
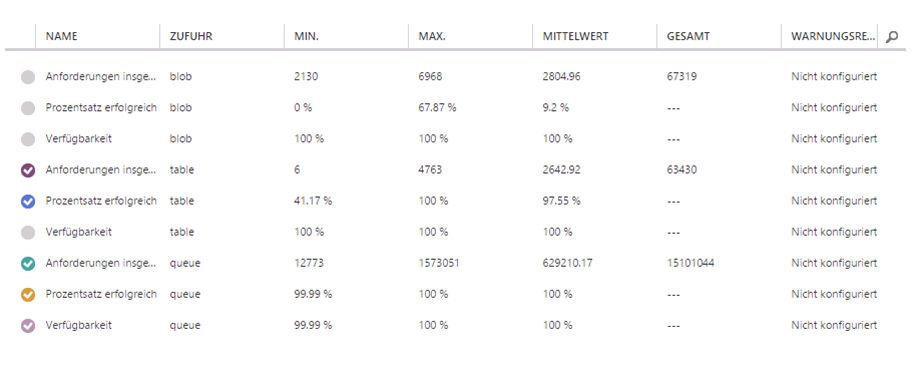
It is all about having the big picture. It didn’t take long to find out what the reason was, but the code itself looks so simple and the infrastructure and all that implementations are so clean and well hidden that it is very easy to forget about.
Mind the infrastructure!
P.S.: The fix didn’t satisfy me at all. To create all these messages in a long running process the service bus message must be completed beforehand. I just added another asynchronous task for the creating all the messages for the cloud queue, so the message can be completed immediatly. But that means when anything breaks that processing, it will be incomplete. The garantuee that the message will be processed again in case of an failure provided by the service bus is gone.
As this is “only” being done very rarely as the start up of the productive and development system this is not too problematic but would be an issue for all the others. Any suggestions about that?