I recently had some discussions about TDD. I personally never tried to accomplish the procedure seriously. So I wanted to invest a little time to understand if it does fit to my needs, especially if it is more effective in short and long term perspective.
I wanted to use a simple example. Not too complex and not too simple. There are some pretty good samples for exactly that purpose, implementing small solutions at Clean Code Developer: Coding Dojos. It is unfortunately in German, so you may want to use online translation to get the picture.
I selected an example because the task seems simple, but there is some serious work to do with the data that is going to be handled: Bank OCR. Let me shortly explain the task in question. It is certainly not about “real” OCR recognition. This would go much too far. It is simple, but nevertheless leaves some room for sensible problem-solving strategies. Actually all these tasks on that web site are made exactly for this. It is not about the best code ever written. But
- how one approaches a problem.
- how one understands the problem and probably separates it into smaller pieces until every single problem is simple to solve
- what considerations are taken into account
- maintainability
- extensibility
- understandability
Let’s go into the details. Btw, if the explanation takes too long, you may want to have a look onto the results in clean code developer samples in github.
The base of the program is an ASCII input file. The file shall look like the following:
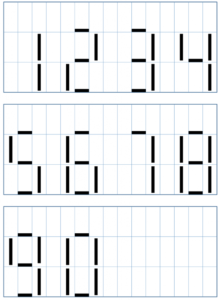
Every number occupies three lines and three characters in a row. Visualization of charaters are done by spaces, pipes and underscores. Between every single character there is a space, expect the last character in the row. There it ends with an carriage return.
The program shall be an executable that takes as the only argument the name of the file.
C:> bankocr datei1.txt
1234567890
815
42
07
In the first run, the file will only have valid numbers, in the second run, it should show per line at least one character was invalid.
C:> bankocr datei1.txt
1234567890
errorneous line
42
07
The file name of the assembly is obviously therefore also specified and there are multiple rows.
The start of all thoughts is always the data.
Sitting in front of the screen thinking about the problem was my first task. This is how I always approach a problem. I don’t code, just thinking. The start of all thoughts is always the data. Consider that to be my comfort zone. It doesn’t work better for me thinking in classes and starting with an obvious “OcrProcessor” class.
You may want to think shortly about it and go on after it to be able to compare your thoughts about the data with mine. Let’s start:
- Every number has three lines. Obviously I need some kind of data class to picture exactly three lines of the text file. As the data must be printed in lines as it was read, each model needs an additional indicator which lines were read originally.
- Every number has three “columns” or characters. Also here I create a data class to picture every single character. The line indicator is necessary as well.
- The next thought was about how to get this three lines of three character with actual three different “markers” – space, underscore and pipe processed to convert it into the “real” number. From code point of view too many indicators often gets messy. My conclusion was that from the programmatical point of view, actually there are only two markers. Characters that are set (pipe, underscore) and charaters that are not set (space). Being a programmer, let’s think in “0” and “1”. That makes processing a lot easier as there is exactly one point in time, where all characters in one number will be transformed in “0” and “1”.
- Still there would be three lines of characters. Actually there is no need for these three lines. Concatenating all three lines to a single one will have the same result and the same uniqueness but will be easier to compare
- Finally there will be the need to represent all this information back to the consumer. Also here a data class is needed. The line indicator is necessary, the computed list of numbers and another indicator, if this line has only valid numbers or not.
To wrap up, have a look into the data class I wrote at first. See full file.
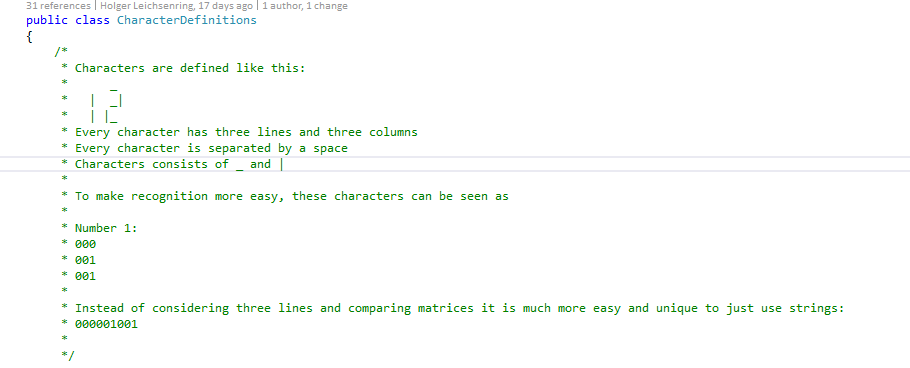
With that thoughts in mind, and actually with all four data classes in place after some minutes, I can start the implementation.
Considering TDD, I guess I did something wrong. I did not write the test at first and let it fail. Anyway I now have a very good idea what is going to be accomplished. But wait. Can I? No, I don’t know what to write right now. Again I sit back and think. Which components do I need?
I do sit back and think about the solution before I start to code. Always.
Considering my data classes – where you can argue if it is really necessary to have the post fix “Model”, guess this is some kind of philiosphical question or a matter of taste – I obviously need functionality that fills that models will life.
- To fill up the LineModel, the textfile needs to be opened and read out. As this is a small sample I didn’t think about memory consumption so file is just read into memory. Each model will hold three physical text lines.
- After the LineModel had been read another component can take over the information and create CharacterModels out of each LineModel
- Next step is to replace the characters in each CharacterModel by “0” and “1” and concatenate three lines into the specified single one
- Now it is time to bring up the “real” number by comparison if the CharacterDefinition defined in step before does exist in my list of existing characters.
- Last but not least the OcrProcessingModel must be filled up by all numbers plus information of the line where it had been read out
That’s it!
I immediatly started to write the code and found myself writing the LineReader first. As this fills up my base data classes it was quite natural to start with it.
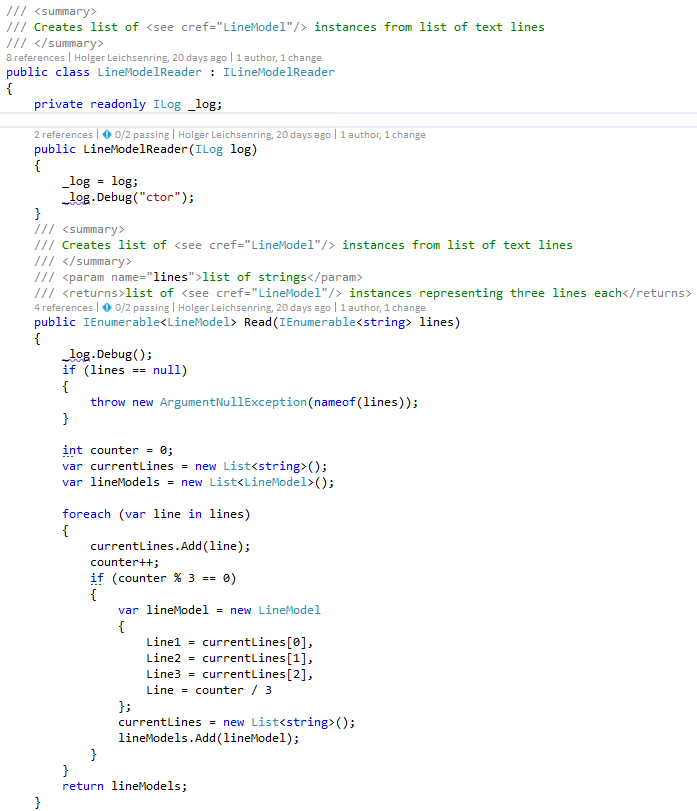
As you may recognized I use dependency injection with Windsor Castle. You may want to have a look onto the following articles to get a deeper understanding how the coding looks like:
- Handy time measurement with Windsor Castle AOP
- Logging in log4net and Windsor Castle in c#
- Coding principles: Are extensions the beauty of the beast?
- What’s wrong with that: Do not only code the happy case
This function is pretty straight forward and due to it is very small hard to do any mistakes when writing it. This is one of the main goals to separate each problem to really small ones. Most of the code is just written and works pretty much directly.
The class just takes over a list of strings and create a model with three lines also adding the information about the current line. It certainly doesn’t check for uncomplete models, as this is still a simple sample and doesn’t need to be 100% complete and defensive.
Next functionality shall take over the formerly created classes and create CharacterModels out of it.

Again, pretty simple. Please do not value the single lines calculating the number of iterations, and how to get out the correct string. Certainly, from the maintainability, readability perspective as well as the defensive coding perspective this can be improved a lot. Anyway, again very simple code just reading out the characters from the model. I actually thought instead of method “Read” in a “Reader” component a converter would have been also appropriate.
As you may recognize, I didn’t get out of my comfort zone. I didn’t do TDD. I just write the small pieces of my program and wire them up. Let’s summarize that later on, I would anyway put your attention onto the fact that I implemented interfaces in both classes. When implementing interface there should be a reason. This is usually the fact that the same contract is used by at minimum more than two parties. When it comes to automatic testing, especially in the environment of dependency injection this is going to be a problem. Because the code needs to be changed because of automatic testing.
The code needs to be changed because of automatic testing. Anyway.
As said, this is not a problem of TDD but of automatic testing. I don’t want to put an empty ctor in the class, neither I like virtual methods in all classes too much to have the possibility to do sensible mocking of the classes when doing automatic testing of behavior and functionality. So the interface looks like the smaller price. Anyway this is a price to be paid, otherwise the automatic tests will be much more complicated to set up and maintain.
The next step is to convert the data in these models to “CharacterDefinitions” replacing the pipes, underscores and spaces by zeros and ones and create a single line out of it.
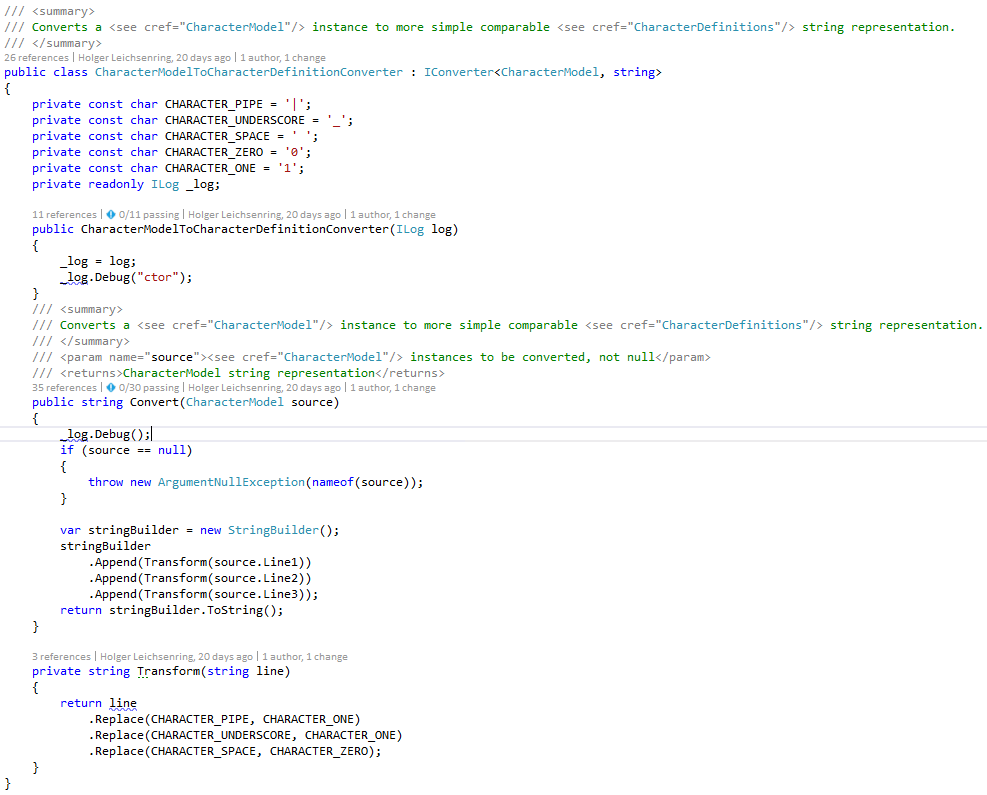
Talking about naming conventions, people tend to name constants differently, the same applies to strategies about logging. Let’s not go into the details about tastes, philosophy and get religious about it. I personally do perfer certain strategies because they worked well for me and the teams, but finally always the team decides, not the architect.
There are just two parts missing, the conversion from the character definition to the “real” number and actually putting together all the single pieces and let it work. You can have a look onto the conversion here. Directly moving forward to the “OcrProcessor”. Here we go:
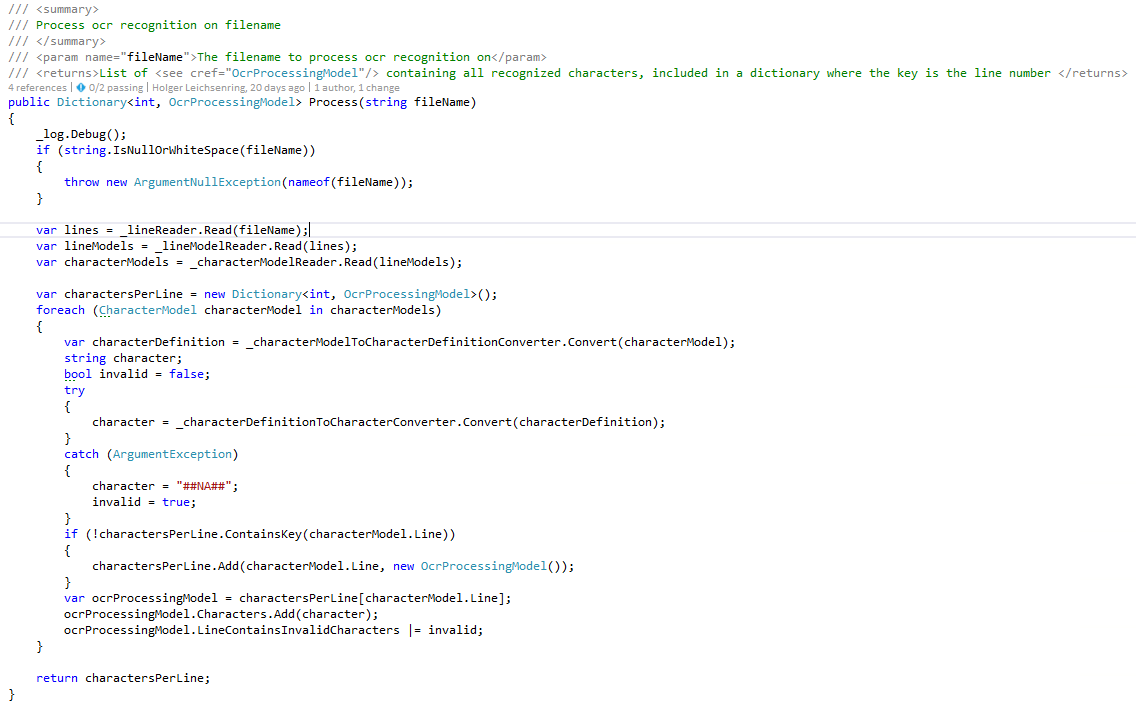 Putting all the functionalities together, the procedure is pretty simple. Getting all the lines from the file, reading out the Line Models. Afterwards reading the CharacterModels from the Line Models and then converting each CharacterModel to a CharacterDefinition. The final conversion from the CharacterDefinition to the “real” number is done within try catch as failing in this particular point is part of the task and needs to be communicated to the caller. Another model, the OcrProcessingModel is set up for every single line, numbers are added to that. Results is a list of characters per line plus an indication if there have been any unexpected/ faulty characters in a line.
Putting all the functionalities together, the procedure is pretty simple. Getting all the lines from the file, reading out the Line Models. Afterwards reading the CharacterModels from the Line Models and then converting each CharacterModel to a CharacterDefinition. The final conversion from the CharacterDefinition to the “real” number is done within try catch as failing in this particular point is part of the task and needs to be communicated to the caller. Another model, the OcrProcessingModel is set up for every single line, numbers are added to that. Results is a list of characters per line plus an indication if there have been any unexpected/ faulty characters in a line.
My program is now moreless completed, but what about the tests? Starting with the data let me move to some kind of bottom-up implementation. When the data definition has been finished I just started with the most simple functionality filling up data and moved up to the ocr processing where I can simple assembly all the single parts.
No single test written up to now but the program is completed. Anyway, let’s have a look onto the tests I wrote afterwards.
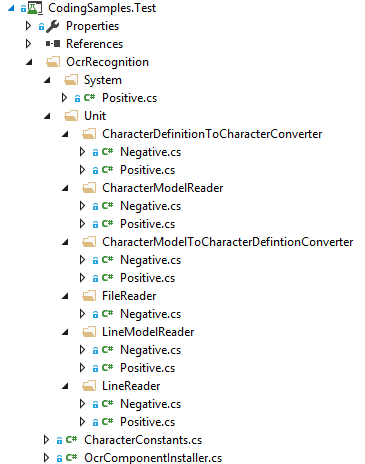
I did two different kinds of tests, system (aka “integration”) tests, where the whole program is going to be tested if it does work correctly as well as unit tests. Tests are mostly separated into Negative/ Positive tests. This could also be done in a single class but from my point of view it is valueable to directly see in the file structure of the tests where I check for expected expections and where I do expect properly working functionality. Have a look onto the github sources.
Again don’t expect to have comprehensive tests. Anyway if using TDD or not on one hand I don’t think that 100% coverage is an effective strategy. People tend to loose focus onto the functionality that is important to test by replaceing it just but the pure number of tests. That may feel well, but very focussed tests (read as: the right tests) telling the real story while they aren’t so intensive in maintaining are much more valueable. On the other hand it is very easy to just overlook the necessary tests anway, so actually the developer needs to know what the program is all about and do the right thing.
Not going too much into the details of the tests I’ve written, the real differences between the procedure I took and TDD are
- The point in time when I write tests
- The bottom-up strategy starting with the data and with the classes filling the data with life instead of top-down starting with an imaginery OcrProcessor class and do it the other way around
- The fact that TDD developer need to think about the most sensible tests in the first run, while I do it afterwards
- The fact that with the procedure I took there is a higher probability that the developer just skips tests because he is running out of time
- Probably the tests look different and tests different areas in a different way
Do you see more differences? Would it be correct to say that people anyway tend to be different, so for one team TDD does fit perfectly because the members of the team want to have the top-down procedure, because it does fit more to them. While another team likes to do it the way I did, thinking about the data and program at first and caring about tests afterwards? Does it make any different in terms of the quality of the developers applying one of the strategies?
Is TDD with top-down strategy more efficient than starting with the data and implement bottom-up?