Quite a while ago I had a good talk with an colleague about “to log or not to log – that is the question”. 😉 That was a longer discussion, and a lot of questions had been raised:
- Shall we do logging?
- What shall be logged out?
- Should we create a log library by ourselves to have it completely under control?
- Does a log message pollutes the actual code?
- Does AOP pollutes the code, when I add interfaces/ virtual methods for logging reasons?
- How can Dependency Injection help us?
- How to put the hurdles of logging that deep that nobody will complain about doing it?
Basic requirements on new software
Let me come up with a little background information. About three years ago, pmOne AG, the company I do work for, decided to completely rebuild a certain piece of software. It was a full client before. Some requirements had been changed, so it should be recreated with a lot of constraints that the full client couldn’t offer:
- It shall be scalable.
- Being able to scale up with multi-threading
- Being able to scale out with multiple machines
- It shall be job-based. If parts of a certain processing fail, not the complete processing shall be restarted, but the pieces which failed
- It shall have a web-based UI
- It shall have a web-based API to remote control it
- Is shall be capable of starting job on a scheduled base
- … the list has been long
Pretty considerable requirements, let me introduce the most problematic one: It shall automate the “real” Excel application running as a service. Quite a challenge. Seriously.

Base infrastructure decisions
We had to decide which technologies to use, what the basic infrastructure for this piece of software is, what coding principles come into the play.. Let’s summarize that:
- We’ve chosen log4net as the logging library. The answers to the questions above in just a second
- We’ve chosen Windsor Castle as Dependency Injection framework
- The coding principles are mostly SOLID, plus some sugar. You may have a look onto Evolution of methodic where I described how I developed a certain set of rules. Or let’s say, how the code taught me what I did wrong so I needed to do things differently to survive 😉
Answering the questions
Most of the questions had been answered pretty fast:
Shall we do logging?
Sure we need to. We wouldn’t have any possibility to find out what is going wrong on customer site without it. For more of the reasons have a look here at How to do sensible logging in c#
What shall be logged out?
The most important information from my perspective if the complete execution path of a program. We need to put out information in different levels. The log shall not make a programm less performant when it runs on a customer’s machine. Verbose information shall only be logged when necessary. Five levels of logging are pretty usual: Debug (aka verbose), Information, Warning, Error, Fatal.
Should we create a log library by ourselves to have it completely under control?
Sure we could do that, but I guess there are a lot of reasons against it:
- Writing log libraries is not our core competence
- There a certainly a lot of people outthere who are more focussed on that topic and have more experience
- When it comes to multi threading, logging is not an easy task
- When thinking about possible targets of logging (relational database, file, xml, json, …) it is quite time consuming
So actually, no, it didn’t make sense to us.
Does a log message pollutes the actual code?
This is a pretty philosophical question. I recently had a discussion about that with a former colleague of mine. They are in the middle of starting to work completely after Clean Code (which I appreciate, actually). When applying this, it seems to be pretty helpful to not getting religious about the issue. People complained about, log should not reside in the code but being completely kept out of the code, thus going in to the direction of AOP. That’s fine by me, AOP does make sense, but also that comes to a price. Most important thing from my point of view: Keep it practical.
Does AOP pollutes the code, when I add interfaces/ virtual methods for logging reasons?
Yet another discussion. As stated above, also AOP comes to a price. When just watching a class and there is an interface defined for it, the humble developer may think that the interface is there because there is an alternative implementation. Using virtual in all methods the developer may think there is inheritation of that class. Changing program code for logging is as nice as choosing an architecture because it should be better testable. But it is a trade off. You and your team may decide what your trade off is. Because there is always at least one, right?
How can Dependency Injection help us?
We did use dependency injection from scratch here. Instead of using a static reference to a singleton (which is the default pattern for log4net) we can introduce the logger as part of the constructor or as a property. That’s pretty handy. Let’s have a look here:
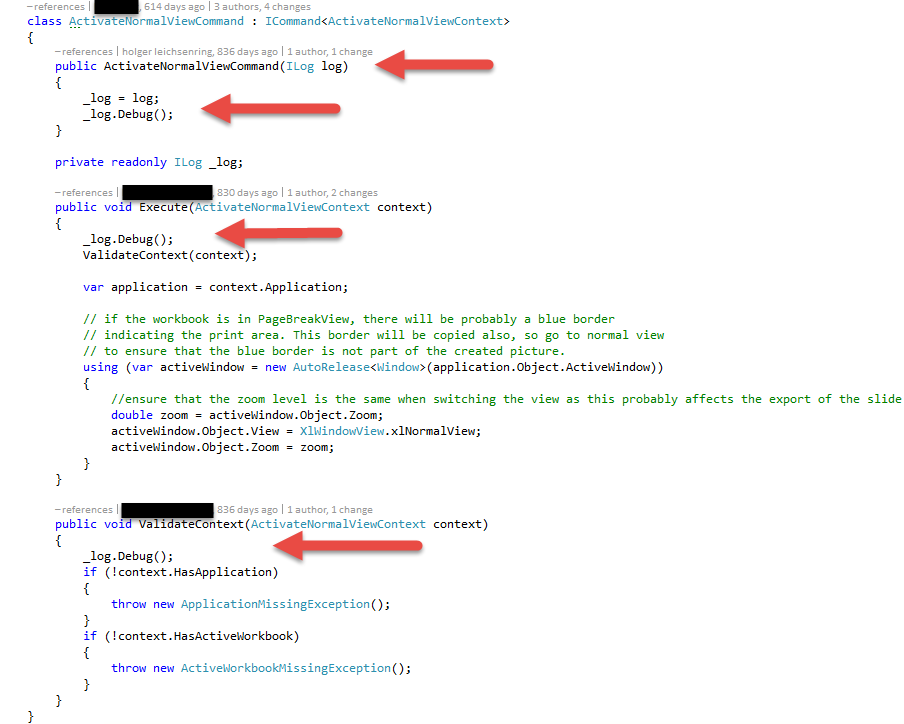
I’ll discuss the details later, just a short explanation to the ctor:
- The ILog interface hides the actual log interface of log4net. If we ever would like to change the library behind the scenes, we don’t want to be forced to do changes in every single class.
- This is created as a log instance for this class. Actually following the log4net default pattern without the overhead of adding the instance with a static reference to the logging library and have a static field for it in the class.
How to put the hurdles of logging that deep that nobody will complain about doing it?
We don’t want to force people to write a lot of texts to do logging. The result of forcing people doing so, is that the logging information is bad or it is not done at all.
Create the basic infrastructure implementation
Windsor Castle is available as a nuget package. To work properly with dependency injection, all parts of the program are available as services. The result of working with dependency injection and the coding principles we apply is a lot of classes. This must be taken seriously. The complete product now has pretty much 3000 files. There is a strong need for clear structures. I did discuss these Coding principles: These assembly/ folder structures… suck. You may want to have a look onto it.
Just some word to that really high count of files. Thi again is a trade off: Either the complexity is inside of bigger classes or the complexity is in referencing between a large amount of very small classes. I do prefer to have classes that follow single responsibility principle. They are easier to maintain, so when I have to choose my death, I’ll always go for small classes and use some kind of mechanism to inject functionalities into these.
Going with dependency injection, there must be at least one container where all the services can be registered to. We did implement that with Service Locator pattern. Beside that single class, we use the Installers interface of Windsor Castle to group and categorise services. With that functionality, installers can be easily assembled and added to build up the functionalities the program actually needed to be capable of.
In MVC & DataBinding: What’s the best approach? I added a small sample of the dependency injection and log4net implementation in a public git repository here. Let’s assume there is more than one assembly, may be even more than one project or product. Some functionality is always “common” to let most of the programs.
It is beneficial to create the base architecture right away from scratch, even with complete new programs.
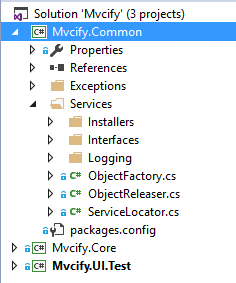
Yes, sometimes it is not crystal clear what the base requirements are, but this structure did apply to the vast majority of products and projects I did have to write.
Here you have the ServiceLocator in the first place, two other classes called ObjectFactory and ObjectReleaser. The main structure also shows a folder for installers as well as for the logging functionality. Let’s have a short view onto the Service Locator implementation:
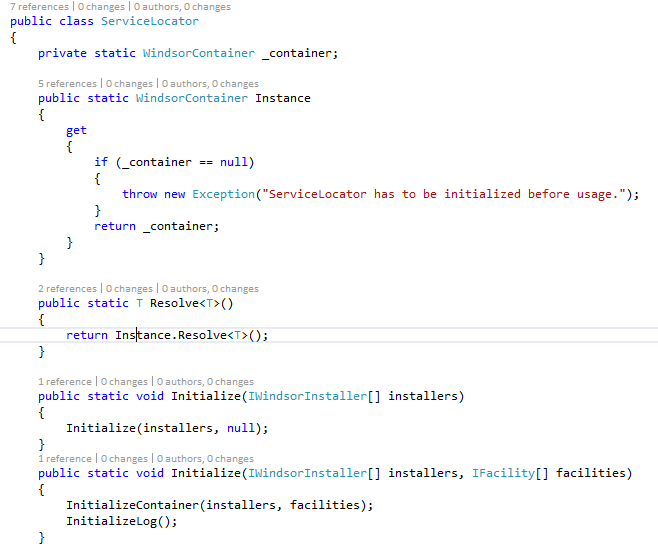
Not too surprising, this is a singleton implementation of the WindsorContainer. Additionally, there are two Initialize methods, that I would like to go into more detail. Shortly before some theory: To not make the Singleton/ ServiceLocator an antipattern, it must be ensured that there are as less as possible references to it. The ServiceLocator is the common and central point of registration. In best case, it is only initialized, top e.g. root services are called and then it is never accessed again.
Let’s have a look onto the WindsorInstaller here:
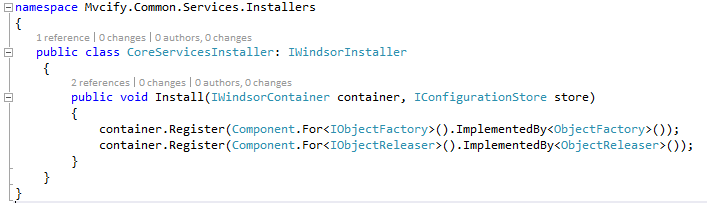
It adds ObjectFactory and ObjectReleaser. What do they do?
ObjectFactory: If there is ever the necessity to create a certain component on the fly instead of getting it injected into the class directly by Windsor Castle, direct references to the ServiceLocator shall be kept as small as possible. When there is the necessity to resolve services directly, we do use the ObjectFactory instead of a direct reference.
ObjectReleaser: When object are resolved “manually” like described above, releasing the objects must be handled by the caller. Windsor Castle then doesn’t garantuee proper resolving as it doesn’t have the creation under control.
But: Where is the logging registration?
Logging needs to be handled differently. When injecting the log instance into a class, we need to know some details about the type the log is injected to. At least the name of the class is necessary to avoid having to type this name in all statements to get a sensible log out of it.
Logging is introduced as Facility.
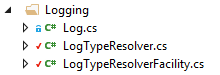
In a facility, Windsor Castle allows the developer to create the instances with the full information about the object to be created. First it needs to be registered. You just need to implement a certain interface for registration:
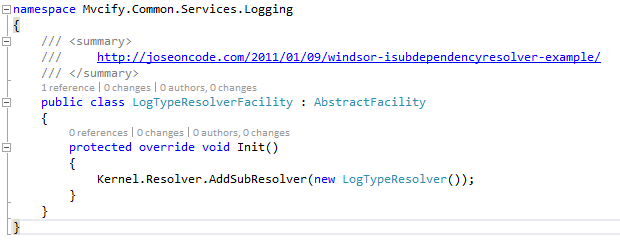
Finally the LogTypeResolver class needs to implement the actual functionality:

The resolver uses the static Log4net LogManager to retrieve the particular instance for the requested type. That is passed over to my log implementation. There is exactly one central point in the code that references log4net. That makes it incredible easy to switch frameworks if needed. And, it finally give the possibility to let the developer inject a log instance that is created exactly for that class.
Where is the initialization of that facility? The logging facility is considered as a functionality that shall always be in place. So it is placed in the initialization of the container itself. You may decide that differently have handle it from the outside.

The results: Usage and log file.
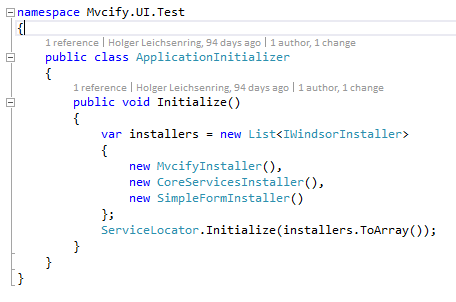
Have a look onto ApplicationInitializer in tests assembly. It collects all necessary services via the installers, and therefore creates the actual functionality of the whole program. This is pretty flexible while being straight forward.
For log4net being able to run, it is necessary to have the right information in app.config or at runtime. For this project I used the first option. There are plenty of so-called appenders out-of-the-box. You can even write your own. For this sample I used a simple RollingFileAppender that does fill up log files up to 5mb, and then rolls files to at least keep 5 files in a row. For the details just click app.config.

When having that infrastructure in place, having class-dependent logs is as easy as just adding another service to constructor.
We do apply logs in every single class, in every public method. How did you implement your logging functionality?
UPDATE:
I was asked why do logging like this, when the upcoming result may look like a call stack. This is actually also given by Stack Trace. There are two things, that are actually pretty different from call stack and Stack Trace, that I think are valuable:
- This log as simple as it is describes the full execution path of the whole program. Certainly it only does that when setting log level to debug. What is part of the execution path? Basically the order of calls of all public methods. While the Stack Trace can tell you which calls led to the exception, this log can tell you the full story about what happened in which order.
- The infrastructure of logging allows you in any place to add information beside the pure method name which I consider to be the minimum. So whenever you detect you need more information in a certain place, it is not problematic at all to add what you need in place.