Part 1: Analysis & Design
This is the first of six articles about how an IoT project with certain constraints and prerequisites was implemented. I have to confess, I never spent so much time on different approaches how to implement a certain piece of software than on this.
- Part 1: (this one) Analysis & Design
- Part 2: Let’s go with containers
- Part 3: What about alternative deployment options?
- Part 4: Going on with alternative deployment options
- Part 5: Final architecture & learnings
Help me with this IoT project. What’s the architecture?
Half a year ago a colleague of mine asked me to help. He was in a business analyst/ project leader position and searched for somebody who can help on a specific scenario. Consider this:
- There is already a system which captures about 14.000 sensor data. It runs in Europe as well as in China.
- Data shall be pushed to an internal implementation around an Azure Data Lake.
- From there it shall be accessible from Power BI to visualize reports on that base of data.
- Data shall be read every 30 seconds for each “plant”. There are multiple in Europe as well as in China. It needs to be configurable. Sure there are more plants to come.
What’s the architecture for this?
We needed to go more into the details. It’s always the same kind of questions for getting understandable requirements for both sides. Let’s name them shortly with a short information about which kind of capability is meant:
- (Scalability) How many sensors need to be captured?
- (Deployment) Where is the system to be developed expected to live? (Cloud, On-Premise, Raspberry Pi, smart watch? Okay, just kidding)
- (Scalability) How long is an information allowed to take end to end? (schedule-read-write – Let’s not talk about “real time” here. Let’s stick to “as fast as possible” or deal with the answer in ms)
- (Availability) What shall happen when the system is not available?
- (Availability) What shall happen when the system is under heavy load?
- (Resiliency) How fast must the system be back to work in case of desaster?
- (Deployment) Are there any prerequisites in terms of technology?
- (Data) What does the data look like that is going to be read? (Size, structure, format)
- (Data) How does the data shall be stored? (Size, structure, format)
- (Data) Is there any kind of operation that needs to be executed on data between read and write? (Transformation, enrich, clean up, …)
- (Logging, Monitoring) What kind of information is necessary to understand the system runs fine? (count of data per second, vms/ services running, health checks of apis, …)
- (Security) What kind of data do we move? (internal, public/ personal, impersonal)
- (Security) How is the system to be expected to be reachable?
- (Security) What kind of authentication is needed where?
- (Security) Is there any physical user wanting to interact with the system/ does this program need a user interface?
- (Cost Efficiency) Is there any expectation about costs?
- (Business) What’s the benefit for the business for this project? (Cost efficiency, Accessibility of data, Insights, Speed, Quality, Prediction, …)
First sketch
After a longer talk about the requirements, I came up with a small sketch of architecture.
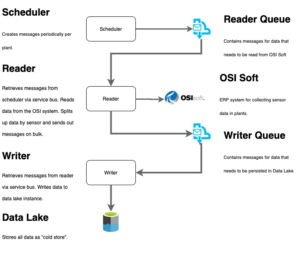
This is certainly pretty rough, but shows the first and from my point of view most important rule and thought: Decoupling. There are main actors in this architecture:
- Scheduler: Needs to push messages every 30 seconds per plant to start reading process. I was told historic data shall also be read. This requires more thoughts.
- Reader: This component shall retrieve messages from the scheduler via a queue. As we stick to Azure a lot, I used Azure Service Bus Queues here. These messages describe which information shall be read from OSI Soft. When information had been read, data needs to be put on another queue. Reader shall not know anything about what is going to be done with the data, it should just read and send.
- Writer: Retrieve messages from Reader’s queue(s) and write this data to an Azure Data Lake.
Architectural intentions and reasons
The overall architecture is thought like an onion architecture. Every piece should be replaceable in a minimal invasive way. To make this clear, just a few bullet points:
The less decison makers in the system, the easier to maintain, understand, enhance.
- Every component should only have one responsibility.
- There shall be as few decision makers as possible. The less there are, the more work is “just” a matter of scaling the work load. Also exception handling is much easier.
- The decoupling method of choice is – not too surprising – a message broker system. This guarantees an important approach: A message must be self containing, just representing information and does not have any functionality. That means, the developer/ architect needs to think beforehand how information/ data need to flow. It is easy to enhance and scale. Certainly every technology approach comes to a price. So there are also drawbacks. I will go into more detail on one of the later posts.
- The Scheduler does not need to know who will read information from OSISoft. It just sends out when and what needs to be done. The scheduler is not responsible for who does it and if it worked.
- The Reader does not care about who sends the messages on the service bus queue. It doesn’t matter if the scheduler is an on-premise python implementation or a (Serverless) Azure Function.
- The Writer does not care about how hard it is to read out information from OSISoft. The only reason for this component is to populate the persistence, in this case an Azure Data Lake instance.
- All components are pretty decoupled.
Just some samples why this approach seems sensible:
- When the persistence needs to change, let’s say a data lake is not fast enough on reading, only Writer component is affected.
- When the frequency of reading information shall be adopted, only the scheduler is affected.
- When reading information is too slow, only the Reader component is affected.
It’s all about making developers, dev ops and maintenance guys’ live easier.
Okay, which technology?
Currently, my company sticks to Azure. So the provider is in place, but we anyway needs to answer some questions:
- Do we want to be as provider independent as possible?
- Do we want to be serverless or have dedicated resources?
- What kind of prerequisites do we have?
There are a couple more of these questions, but let’s stick with the latter. There is one prerequisite that really is kind of problematic. The only library that is available for accessing data from OSISoft is a proprietary .net Framework 4.8 lib. This lib has its age. It is visible in the “object model” that has been implemented and the general approach. I would need to use windows containers on a windows machine.

Using containers isn’t more fun with Windows
Anyway, containers had been the first thought. There is a 230mb setup that needs to be executed on a windows machine to make this .net framework lib running. I did want to avoid having VMs flying around, so let’s try containers for the Reader, Writer and Scheduler.
What’s next
In next article, I describe my approach for getting the OSISoft setup being available on docker on a windows machine. Scary, I know. Follow me into the darkness :-D.