
It is some time ago that I left my former company which work in Business Intelligence sector and has roughly 150 employees. I went to a much bigger company, which is quite international with roughly 54k employees. The business complexities and the pure count of topics are quite different than in small companies.
Bigger companies, different challenges
Being in a bigger company leads to different thoughts and perspectives. It is not only about the fact that developers should work in the same manner, solving the same problem in the same way. Due to the count of people and topics, different topics are raised:
- Heterogeneous technology stacks
- Heterogeneous skill sets
- Providers with software in all flavors of languages and technologies
- Lots of external workers that need to be steered
- Sure, politics
- Lots of legacy software, procedures
- Lots of processes
With all these issues, a common approach of collaboration and working needs to function with small teams and well as with large. It shouldn’t matter if developers use Java, Go or .net. External employees need to be able to jump on that train easily – without spending too much money on education of these people. Legacy software and systems should not have any need to be adopted which would be quite expensive and doesn’t add business value.
Always talking about “what”
People often tend to talk about the “what”. What needs to be done? Are there different projects that need the same “what”? How to combine the necessities, matching resources, time lines, features in detail? Mostly these discussions are done on a very high level which leads to expectations on business side and headaches on IT side.
Let’s talk about the “how”
Getting away from what actually shall be done, let’s put some thoughts on how people should work together. Let’s put a short list of questions on “how”:
- How to present a methodic that is understandable, easy to adopt and easy to learn?
- How to allow development teams to work with their favorite languages and environments?
- How to do that in parallel without blocking each other?
- How do we reach quality standards that everybody apply?
- How do we get everybody to meet documentation standards (developer’s darling)?
- How to automate away all possible manual work?
- How to test all the mess automatically?
- How to test In various ways: Unit tests, load tests, integration tests, …you name it?
The approach of working needs to fit quality expectations as well it needs to be easy to adopt
Stating the principles
To set up the list of principles, let’s think about the people/ roles that are going to fulfill the necessary tasks. Before I start to search for tools, functionalities and all the stuff, let’s shed some light on how I am used to work currently. Let’s just take the latest project I’ve done and check if this would work also for larger teams.
Sampling my personal current approach
The last project I did was a mobile application. Setup looked like this:
- The frontend was implemented as a native iPhone application
- A backend implemented in .net core, hosted in (n) Azure App Service(s).
- As storage, Sql Azure is used.
- For synchronization of data from SAP there are certain components and technologies used: ABAP implementations, IBM WebSphere, Azure Blob Storages, Azure Data Factory and a lot of sql scripts in Sql Azure.
To make a long story short, when the requirement management is done and business and developer team have a clear picture what needs to be done, I usually start working in my favorite IDE. In this case I implemented the backend on my mac with JetBrains’ Rider. I set up the controllers, models, the request and responses, write the necessary code to do the CRUD operations against the database. This is all kind of iterative approach. Some of the data and operations are not yet clear. In the first sprints, communication with front end team is very intense, providing the necessary endpoints for making user interface functional. Mostly going with mocked data and fill it with life afterwards.
There are some issues with this approach. Certainly it works. Certainly it is possible to create high quality code that is tested automatically. What are the main issues then?
- Clear Definitions increases speed: I actually do not like it, when the data and operations on data are not clear. That often lead to several iterations changing existing endpoints and functionality in frontend.
- Mocking in front end wastes time: In the first run, there are no endpoints. Frontend and backend developers start in the same point in time. That means front end developers mock the endpoints, wait for the backend developer to come up with something usable. When the backend is available, there needs to be a check up, if the definitions of the front end mock implementation does fit the actual backend one.
- Communication is spreaded: Communication of the api endpoints is often spreaded over different channels. Email, Teams, phone calls and the like. That makes it hard to follow.
- Development does not scale: Imagine this project wouldn’t have been done by just a few developers. When there are multiple teams implementing APIs that depend on each other, hurdles and redundancies grow exponentially.
- Automatism: Setting up CI and CD has been done by me also. That was kind of manual work, doing explicitely for this project. When the data and the operations on data, the language in which is written and the technology that shall be used to host the program is known beforehand, most of the stuff can be automated without any manual interaction.
- Writing automatic tests is time consuming: At least end to end tests can be implemented automatically when the data and operations are known beforehand.
How can these issues be solved? Let’s put some thoughts into how the actual working model shall be and which roles/ tasks need to be done.
The Roles
Let’s do it like you expect it in the news. Results first.
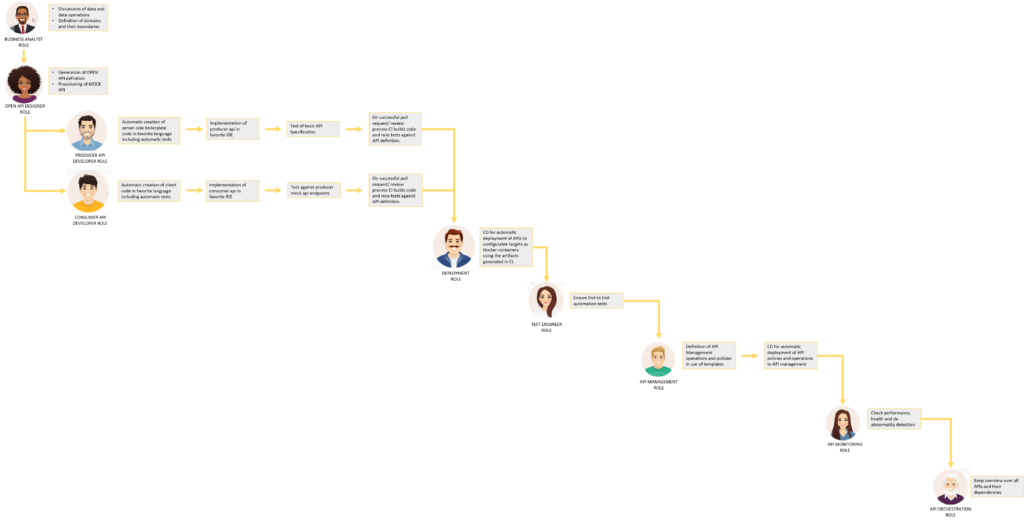
This is the overview about all roles that are necessary to picture all the tasks. Let’s go into details from top to bottom.
What needs to be done in the first step, is called widely Design First or API First. Define the data and the operations on data together with the business. When this is done, the definition of these domains and operations can be put into an OPEN API definition easily.
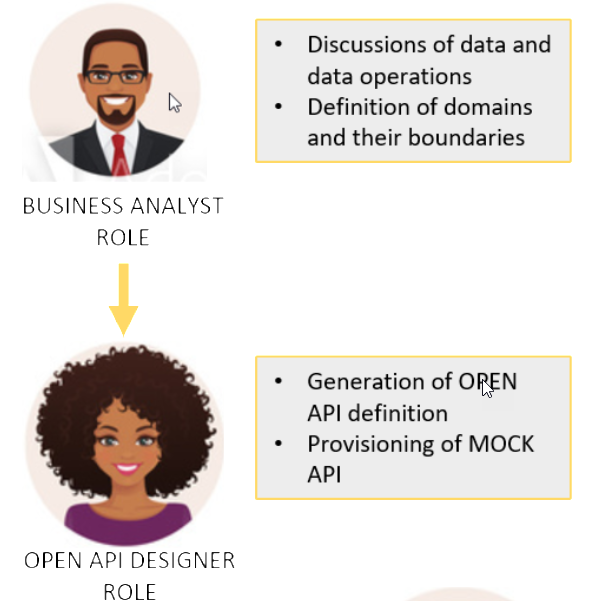
When the API definition is done, and a mock of this definition is up and running, backend implementation as well as consumer implementation can be done side by side without hurdles and blockers.
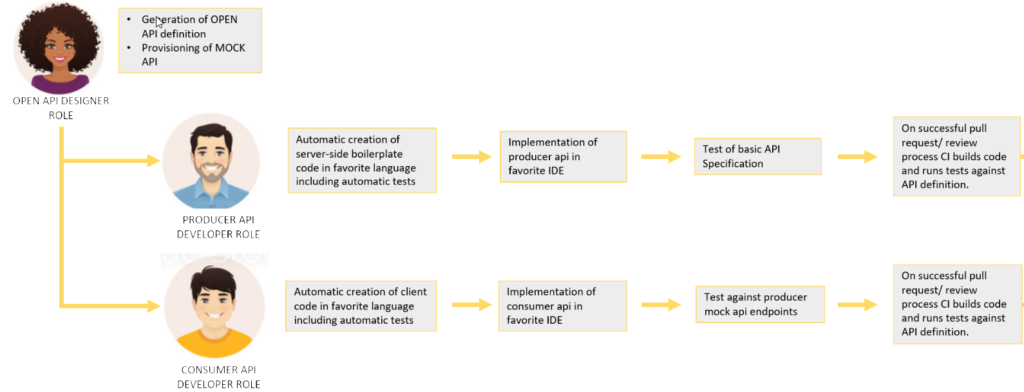
To help developers to speed up implementations and due to the fact that we have a solid definition of contracts about data and operations, it is easy to generate the code for client and server side stub. Developers then can happily implement their magic without additional redundant iterations and without unnessary communication. As the API definition is clear beforehand it should be possible to generate tests against that definition if producer api keeps that contracts. There should be no need to manual CI definitions of the developers, as also these should be possible to auto generate as the code before.
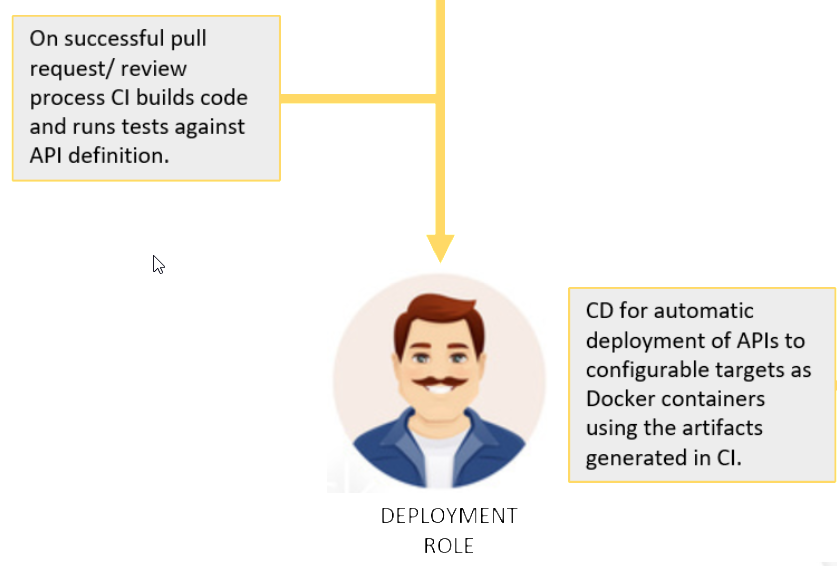
When code has been pushed to code repository, CI has been through, there is only one thing missing. The code needs to deployed to be consumable beside the mock definition. Also this should be possible to provide this in an automated way without having anybody doing this manually.
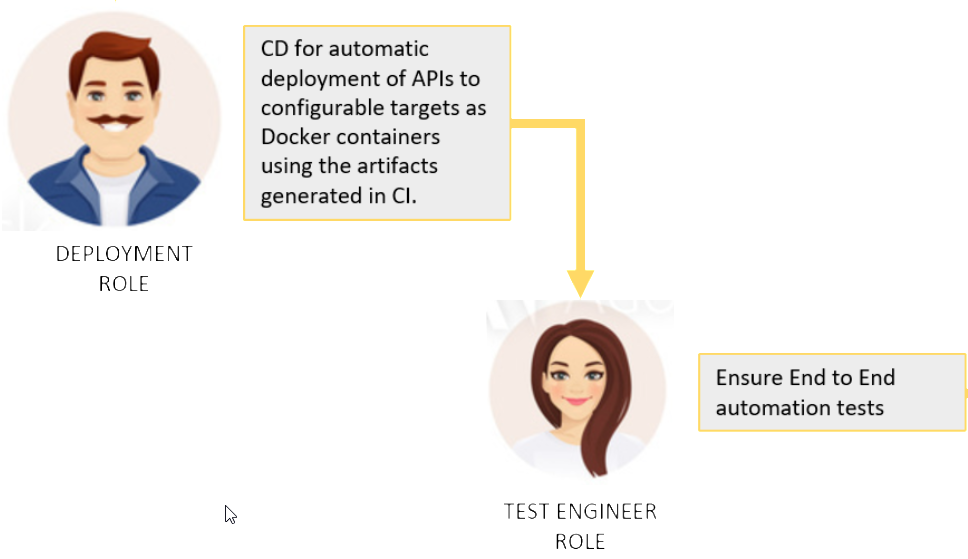
When the producer api has been deployed, real end to end tests can happen. Also here, in best case there is no manual interaction needed. The code for auto testing can be generated from the OPEN API definition.
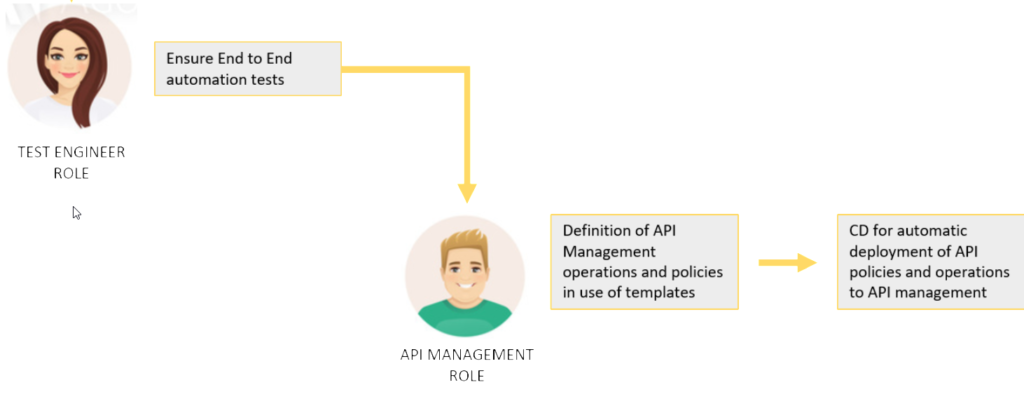
The next step already applies to operations. When the api has been deployed and imagine you have not one or 10, but 100 apis out there, usually there is the need to apply an api management. This comes for multiple reasons that I won’t discuss in this article.
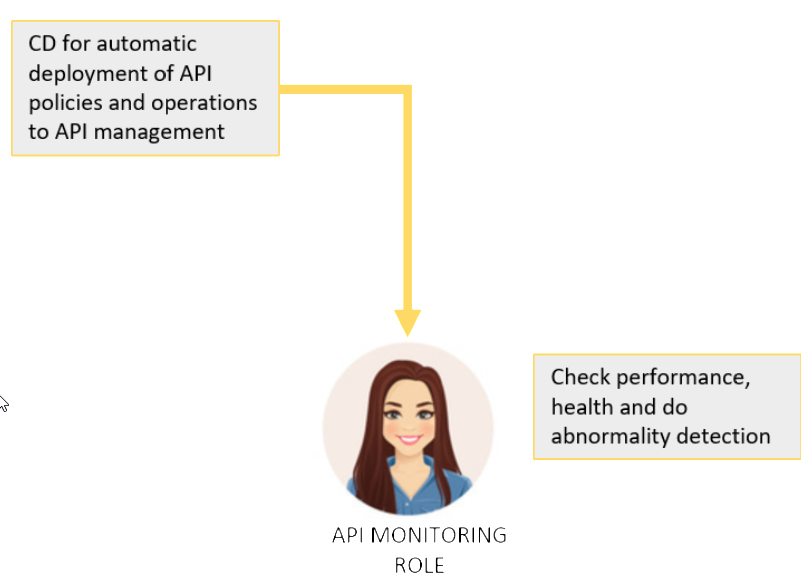
Talking about operations (DevOps to name the buzzword) certainly there needs to be monitoring in place. In best case there is also kind of abnormality detection, that shows unexpected behavior in the possible graph of APIs working together.
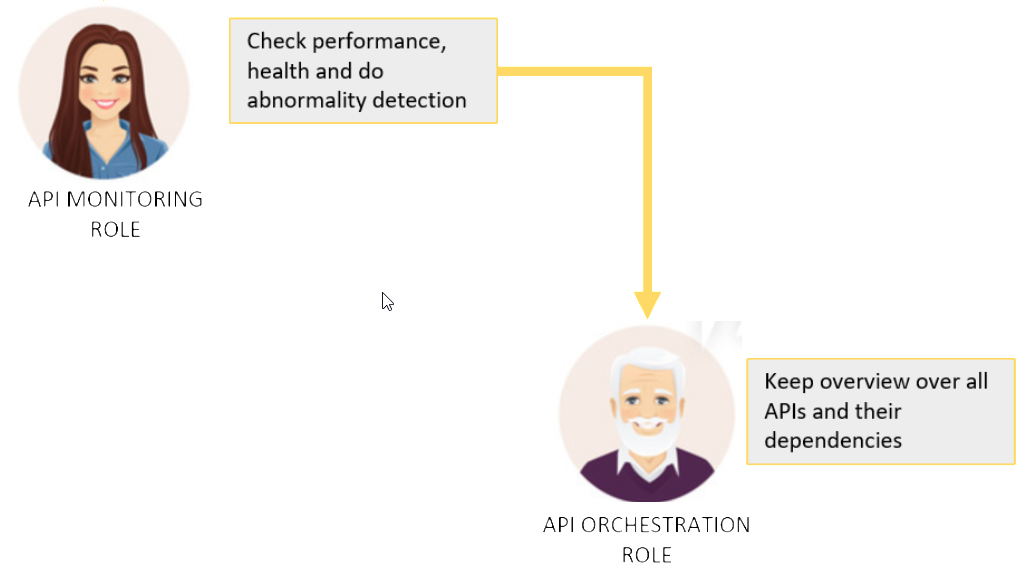
Finally, when having all shipped, it may be necessary to not only know about the graph of apis that is out there, but to visualize it. Not too sure here if orchestration should be done on design time. I think about that like with class diagrams. Since I use dependency injection I do not use this feature in IDEs anymore. I am more interested in evaluation of performance issues and dependencies when I execute the code. I may be wrong with that.
Finally let’s get to the principles.
The principles
Here we are. From all the tasks and roles above, these principles had been condensed:
- Lean & Agile
- API-First
- 100% automated
- Designed for re-use
- Simplicity, please!
- Learning by guided doing
Lean & Agile
So here it is again, the omnipresent agile development stuff. Don’t let me go into too much detail here. I guess, most of you guys heard about it, have an opionion. May be you like it or you hate it, you prefer “iterative” development over “agile” because you don’t like the esoteric component of playing poker about complexity points… The agile development principles finally arrived also to the big companies. I am used to work in iterative development methodologies for years, and I actually don’t mind too much how it is named today.
What I do mind is the Lean Inception methodology. I turned out to be very effective to generate an MVP definition together with all relevant people: business, developers, UX, … If you didn’t hear about it, you may want to throw an eye.
API First
API First actually is interpreted – at least by me – as: Know your data and the operations on data. If you know both, there is actually a high probability that your contract is going to be stable. You want to know more about this?
Know your data and the operations on your data.
Benefits:
- Ease, accelerate and align collaboration of people and technology
- Single methodology, single tool stack, all fits together
- Enable full automation
Approach:
- Design first: Think data and how to use it –
- Just define your API. Don’t implement, just mock.
- Hence, others can start.
- APIs are self-descriptive and adhere to one common API industry standard.
- Focus on your business logic. All complex magic is done for you.
100% Automation
We all know, without automation we won’t get anywhere. As we start with the definition of the contracts, a much higher degree of automation esp. in tests but also in code generation can be targeted.
Benefits:
- Maximize product quality and stability
- Elastic in scale, efficient in costs
- Full transparency on development process
- Boost speed of implementation
Approach:
- Infrastructure as code. Day 1 automation, no excuses.
- Mutual codebase and tooling for all development- and operational-teams
- Programmatic interfaces for all infrastructure services (Monitoring, Logging, Auth, Certs, Containers, Services …)
Design for re-use
Reusability is really not a new concept. When designing APIs certainly, the same domains should not appear in different APIs. Also the same logic should not be applied in different APIs.
Benefits:
- Minimize redundancies, minimize efforts. Do everything just once.
- Quality through collaboration
- Boost development speed
- Engage competition, be proud of your code
Approach:
- All code in one place: General code hub.
- Embrace modularity, think in components for common solutions.
- Build it as if you like to sell or buy it
- Always provide tutorials & examples which allow users to explore components on their own
Simplicity, please!
Pretty much everybody can solve a certain problem when programming in a certain way. Do elegant (read simple) solutions is much harder. It requires experience, good knowlegde about the domain and good analytical skills.
Benefits:
- Split complex problems into small and simple solutions
- Enable and support adaptability to change
- Boost development speed
Approach:
- Build modular software, always: Ensure that every single part of the resulting program can be replaced without affecting other parts of the program
- Favor convention over configuration
- Keep focused, only solve known requirements
- The art of simplicity: Experience, curiosity, collaboration, create boring solutions. Don’t be fancy.
Learning by guided doing
When changing the approach of working esp. in bigger companies, not all people will be able to just follow. And even the mor experienced ones may want to have some coaching. To make this successful, it is necessary to have a concept of how to teach and help.
Benefits:
- Guidance for project, service, product teams and management
- Enforce agile methodology, quality, implementation, documentation standards
- Speed up onboarding and development
- Train and develop/ upskill juniors
- Ease interchangeability of developers between teams
Approach:
- Dev Evangelists included in projects, services and products to coach, train and help
- Lead by example: Practice what you preach
- Leverage infrastructure / tools for instant and automated guidance.
Let the tools [“find the bug”, “fix the problem”, “deploy the change”, …] - Build up sufficient resources with appropriate skill set (>5 years experience)
Conclusion
Having these principles in mind and a clear approach how to solve problem, how to scale teams, how to collaborate and work together, how to ensure there are no unnecessary blockers, the next step is to select the software to help. It is certainly not wanted to fill every principle with life by own development from cost and time perspective.
I’ll go into the details of which tools and functionalities can be leveraged to implement these principles in the next post.
What is your approach to scale development teams?